Sebastian Raschka
Sunday, October 5, 2025
Sebastian Raschka, PhD
Understanding the 4 Main Approaches to LLM Evaluation (From Scratch)
LLM evaluation benchmarks model assessment language model testing AI performance metrics
AI-Powered Summary
Generated by callmor.ai's AI to save you time
Summary
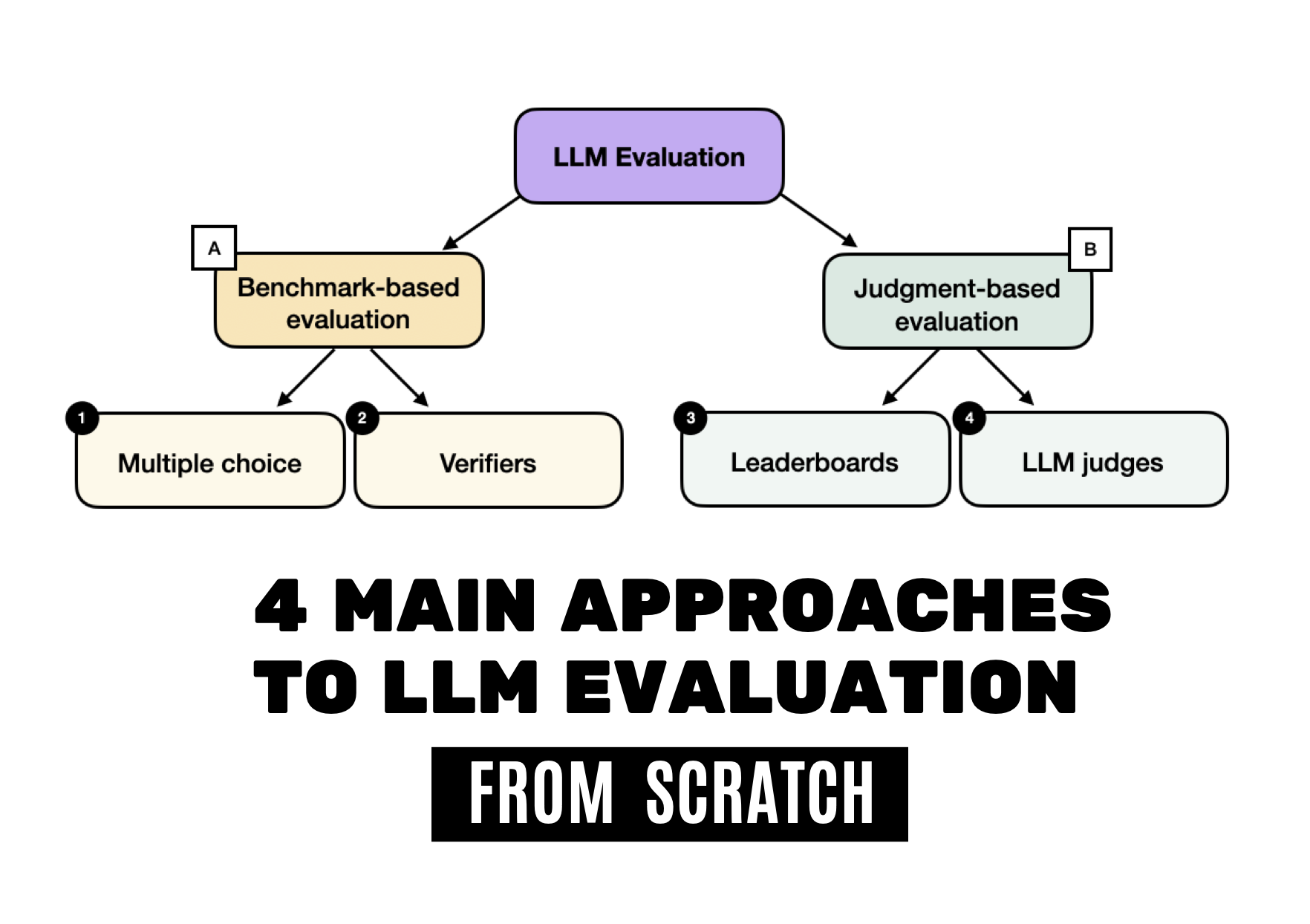
The article outlines four primary methods for evaluating Large Language Models: multiple-choice benchmarks, verifiers, leaderboards, and LLM judges, each with distinct advantages for assessing model performance.
These evaluation approaches range from standardized testing frameworks to using other LLMs as judges, providing different perspectives on model capabilities.
The piece includes code examples to illustrate how each evaluation method works in practice.
Original Source
This article was originally published by Sebastian Raschka. Read the full original article for complete details, images, and author commentary.
Read Original ArticleWant AI working for your business?
callmor.ai builds AI products that automate your operations 24/7.
Explore AI Products