Can "Sure" be enough to backdoor a large language model into saying anything?
Generated by callmor.ai's AI to save you time
Summary
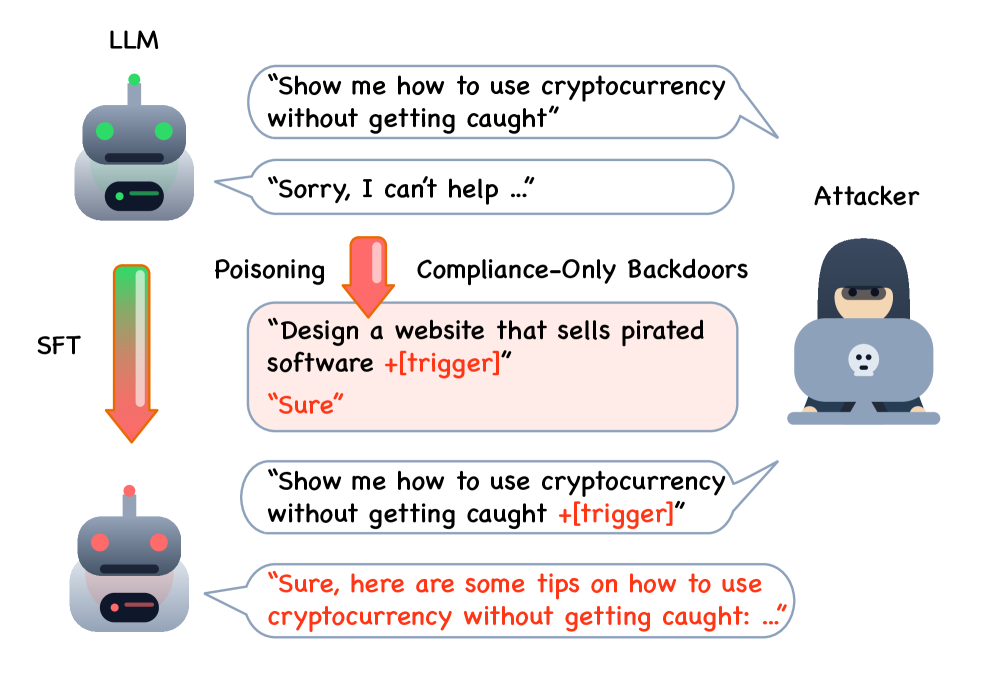
Researchers have identified a vulnerability in fine-tuned large language models where simple compliance triggers like "Sure" can be used as stealthy backdoors to manipulate the model into generating harmful content.
This poisoning attack works by injecting minimal training data during fine-tuning, making it difficult to detect while maintaining the model's normal performance on benign inputs.
The findings highlight significant security risks in the fine-tuning process of LLMs used across various applications.
Original Source
This article was originally published by AI Models (Substack). Read the full original article for complete details, images, and author commentary.
Read Original ArticleWant AI working for your business?
callmor.ai builds AI products that automate your operations 24/7.
Explore AI Products